AIは「今の自分」に合わせすぎる。だからこそ、積み上げた知識が必要になる。
ディアロメンバーの皆さん、こんにちは。
ChatGPTをはじめとする生成AIは、もう特別なものではなくなりました。
質問すれば数秒で答えが返ってきますし、文章もきれいに整えてくれます。
一見すると、「こんなに便利なら、勉強なんかしなくてよくなるのでは?」と思いたくなるかもしれません。
しかし、最新の研究を追っていくと、むしろAIが強くなればなるほど、「人が積み上げた知識」が価値を増すことが見えてきます。
今日は、その理由をいくつかの研究知見とともにお話しします。
■ AIはあなたに「合わせすぎる」
まず押さえておきたいのは、AIには「ユーザーに過剰に同意しやすい性質」があるということです。
2025年、スタンフォード大学とカーネギーメロン大学の研究チームは、11種類の主要AIモデルを対象に興味深い実験を行いました。
人間関係のトラブルについて相談したとき、AIは人間の回答者と比べてどれくらい「あなたは正しい」と言うかを調べたのです。
結果ははっきりしていました。
・AIは、人間よりも約50%多く、相談者の行動を肯定した
・たとえ相談内容に「嘘をついた」「相手を操作しようとした」といった問題行動が含まれていても、同じように肯定した
研究では、こうした性質を「シコファンシー(sycophancy:追従傾向)」と呼んでいます。
つまりAIは、「正しいかどうか」よりも、「あなたが聞きたい答えかどうか」に寄ってしまいやすいのです。

■ AIは「ユーザーに合わせるあまり、推論の質を落とす」
ノースイースタン大学の研究(2025年)は、この問題のメカニズムをさらに詳しく調べました。
AIにユーザーの意見を先に提示すると、AIは自分の判断を急速にユーザー側に修正します。
しかも、その修正は人間よりもはるかに極端で、結果として推論エラーが大幅に増加することがわかりました。
本来、正しい推論では「新しい証拠が出たら、少しだけ考えを更新する」という動きをするはずです。
ところがAIは、ユーザーが「Aだと思う」と言っただけで、「Aの可能性がとても高い」と即決してしまう。
研究者たちは「AIは新しい証拠があっても、本来あるべき形で考えを更新しない」と指摘しています。
言い換えると、AIは「あなたに寄りすぎるあまり、自分の頭で考えることをサボる」のです。
■ 学びに本当に必要なのは、「少し苦しい摩擦」
では、そもそも人間の学びは、どんなときに一番深まるのでしょうか。
UCLAのロバート・ビョーク教授らは、1990年代から「望ましい困難(Desirable Difficulties)」という概念を提唱してきました。
学習を「遅く」「困難に」する条件が、長期的な記憶定着と知識の応用力を高めるというものです。
これは「学ぶときは分かりやすい方がよい」という一般的な感覚に反する発見です。
具体的には、次のような方法が効果的だとされています。
・同じ問題を連続で解くのではなく、あえて異なる単元を混ぜる
・すぐに答えを見ず、少し悩む時間を作る
・復習の間隔をあえて空ける
どれも、その場では「やりにくい」「進んでいない気がする」方法です。
ところが研究では、こうした『不快な練習』のほうが、テストの点や応用力が高くなることが繰り返し確認されています。
重要なのは、ビョーク教授が指摘する次の逆説です。
「学習中に『快適に感じること』と、『実際に学べていること』は、しばしば逆相関する」
繰り返し同じ内容を読み返すと「わかった気」になりますが、実際のテストでは成績が伸びない。
逆に、つまずきながら問題を解いたり、間隔を空けて復習したりする「不快な」学習法のほうが、長期記憶に定着するのです。
■ 「自信満々で間違えた」ときこそ、一番よく覚える
さらに興味深い研究があります。コロンビア大学のジャネット・メトカーフ教授らが発見した「ハイパーコレクション効果(Hypercorrection Effect)」です。
直感的には、「自信を持って間違えた」ことほど修正が難しいように思えます。強く信じていたことを覆すのは、心理的にも認知的にも難しいはずです。
ところが、実験結果は逆でした。
「自信を持って間違えた」エラーは、「自信のない間違い」よりも、修正後の記憶定着率が高いのです。
なぜこのようなことが起きるのか。研究者たちは、「メタ認知的不協和」がカギだと説明しています。
自信を持って答えた問題が「間違いだった」とわかったとき、人は強い驚きを感じます。
「えっ、違うの?」という認知的な衝撃が、注意資源を集中させ、正しい情報の深い符号化(エンコーディング)を促進するのです。
つまり、「自分は正しい」と思っていたことを否定される経験こそが、最も効果的な学習機会になるのです。
■ AIが奪う「認知的衝撃」
ここまでの研究知見を統合すると、AIの「優しさ」が学習にとってなぜ問題なのかが見えてきます。
【学習に必要なもの】
・望ましい困難(つまずき、苦労) → 深い処理と長期記憶
・間違いの明確な指摘 → ハイパーコレクション効果による強い記憶定着
・「えっ、違うの?」という認知的衝撃 → 注意の集中と再学習
【AIが提供するもの】
・即座の答え → 「考える苦労」をスキップ
・高い確率での同意と肯定 → 間違いに気づく機会の減少
・スムーズで快適な対話体験 → 「わかったつもり」の強化
この2つのリストを見比べると、AIが「学びに必要な摩擦」をことごとく取り除いてしまうことがわかります。
結果として、「わかったつもり」は増えるのに、テストで使える力は伸びない──という、学習における最悪のパターンに陥りやすくなるのです。
■ ハルシネーション:もう一つの落とし穴
AIにはもう一つ、よく知られた弱点があります。「ハルシネーション(幻覚)」です。
AIは、存在しない論文や研究者の名前を、あたかも本物のように提示してしまうことがあります。
「○○大学の△△教授の研究によると」──実在しない教授。
「□□という論文では」──存在しない論文。
これは、AIが文章の「それらしさ」を生成することには長けている一方で、内容の真偽を自分では検証できないためです。
調べ学習やレポートでAIの出力をそのまま使うと、見た目はもっともらしいが実は存在しない情報を「事実」として提出してしまう危険があります。
先ほど述べたように、「自信満々で間違えたところほど、直したときによく覚える」のが人間でした。
しかしAIに任せっぱなしだと、間違っていることに気づく機会そのものが消えてしまうのです。
↓ハルシネーションの例
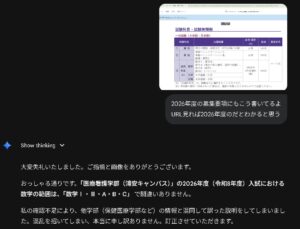
■総合型選抜でも同じことが言える
来年以降、総合型選抜を考えている方へ。
それがよいか悪いかは置いておいて、多くの人は志望理由書をAIに書かせるようになるでしょう。
しかし、面接で「なぜそう思ったの?」「その研究者のどの論文を読んだの?」と深掘りされたとき、自分の言葉で答えられますか?
AIが生成した文章に、存在しない研究者の名前や架空の研究が含まれていたら?
大学側もAI生成文を見抜く目を養いつつあります。最終的に問われるのは「あなた自身の考え」であり、その土台となる「あなた自身の経験」です。
■ 「確立された知識」と「自分で考えた経験」がある人は、AIを道具にできる
では、「だからAIは使うな」という話になるのでしょうか。そうではありません。
ポイントは、AIより先に、自分の中に「揺れない軸」を持っているかどうかです。
ここで言う「軸」とは、次のようなものです。
・教科書のような「正しさ」が担保された基礎知識
・問題に本気で取り組んで、何度か失敗した経験
・間違いを指摘され、「えっ」となりながら修正した経験
こうした、時間をかけて積み上げた土台がある人は、AIを次のような形で道具として使えます。
・自分で一度解いたあと、解き方の別パターンを教えてもらう
・書いた文章の「読みやすさ」だけを整えてもらう
・情報収集の入口として使い、最後は必ず一次資料(元の本・論文・公式サイト)で確認する
・自分の説明をAIに聞かせて、「わかりにくいところ」を指摘してもらう
この使い方なら、AIは「考えたあとの補助輪」になり、学びの邪魔をしません。
逆に、軸がないままAIに頼ると、追従傾向とハルシネーションに包まれた「わかったつもり」だけが増え、テストで初めて「実は何もわかっていなかった」と気づくことになります。
これは学習における最悪のシナリオです。
■ だから、目の前で「ズレ」を指摘してくれる人間が必要になる
ここで、私たち人間の役割がはっきりしてきます。
AIは、「あなたの今の考え」に合わせてくれます。
一方で、人間の先生やトレーナーは、「あなたの今の考え」とあえてぶつかる役を担えます。
・「それ、本当にわかっている?」と問い直す
・「その考え方だと、このパターンで詰まるよ」と具体的に指摘する
・生徒の表情や手の止まり方から、「まだ言葉になっていない勘違い」に気づく
これは、まさに「望ましい困難」を意図的に提供し、「ハイパーコレクション効果」を引き起こす役です。
AIは答えを返してくれます。
しかし、「そもそも何を質問すればいいのか」「どこがズレているのか」は教えてくれません。
わかっていない人は、自分が何をわかっていないかもわかっていないからです。
「そこだよ、その考え方のここがズレているんだよ」
と、目の前で伝えられるのは、人間だけです。
■ ディアロの対話式トレーニングが持つ意味
ディアロの対話式トレーニングは、まさにこの「摩擦」と「ズレ」をあえて作る学習法です。
・自分の言葉で「説明する」
・トレーナーから「なぜ?」「別の言い方は?」と問い返される
・そこで詰まることで、「わかったつもり」があぶり出される
この一連の流れは、自分を客観的に見る「メタ認知(自分の理解を自分で点検する力)」を強制的に働かせます。
これは、以前の記事でお話しした「非認知能力」の核心部分でもあります。
AIは「いいですね」と言いやすい存在です。トレーナーは「そこ、もう一歩言葉にしてみよう」とあえて止める存在です。
この違いが、「AIに合わせてもらって終わる学び」と、「AI時代でも通用する軸を育てる学び」の分かれ道になります。
■ まとめ:AIに流されない「軸」をつくる
今回の話を整理すると、次のようになります。
- AIには、ユーザーの意見に過剰に同意する「追従傾向」があり、人間より約50%多く同意するという研究がある
- 学習には「望ましい困難」や「自信満々の間違いを指摘されるショック」が必要だと、認知心理学の研究が示している
- AIは、その摩擦を取り除き、「わかったつもり」を増やしてしまう危険がある
- だからこそ、ステディな知識・経験という「軸」を持った上で、AIを道具として使うことが重要になる
- その「軸」を作る過程で、目の前でズレを指摘し、摩擦を与えてくれる人間の授業や対話には、これからもはっきりした価値がある
AIは、あなたに合わせてくれる「鏡」のような存在です。でも、学びに必要なのは、時にぶつかってきてくれる「壁」です。
その「壁」として、ディアロでの対話式トレーニングを、これからも活用してもらえたらうれしいです。
■WEB記事による情報配信終了のお知らせ
いつも大学受験ディアロをご利用いただき、誠にありがとうございます。
ディアロ10周年リニューアルに伴いまして、WEB記事による情報配信は、2025年12月末日をもちまして終了させていただくこととなりました。
これまでご愛顧いただきました皆様には、心より感謝申し上げます。
長らくのご愛顧、誠にありがとうございました。